В этой части будем разбираться с текстовыми данными. Как их создавать, преобразовывать, какие полезные методы существуют для работы с этими типами данных. Немного дам вводных про переменные, как их принято писать и какие имена переменным давать нельзя.
Переменные в Питоне
Как уже говорил в статьях ранее, переменная — это что-то вроде резервирования в памяти компьютера места, чтобы положить туда данные. Ну и просто удобно, это как название футбольной команды, не нужно каждый раз перечислять всех игроков и тренера, сказал название — все всё поняли.
Базовые правила для именования переменных такие:
- Они должны быть на латинице, регистр важен. Переменная W и w — разные переменные;
- Они не должны содержать пробелов, но могут содержать нижние подчёркивания;
- Они не должны начинаться с цифр, но могут содержать цифры в имени далее;
- Они не должны совпадать с ключевым словами Питона.
Таким образом имена переменных типа "Ревит", "1Voin", "batya v zdanii", "print" использовать нельзя.
Ключевые слова — это специально выделенные команды, которыми мы создаём циклы, условия и всё такое прочее. Все эти слова вроде for, in, if, else, try, list, continue запрещено использовать, код не запустится. Можете посмотреть список ключевых слов на сайте летпай.ком.
У программистов есть правила, как давать имена переменным. Так как регистр влияет на имена переменных, то переменные pipe и Pipe будут разными переменными. Соответственно, появляется выбор: с заглавной или строчной буквы начинать имя переменной, как делить слова между собою, в общем, по каким правилам писать имена переменных.
В Питоне рекомендуется писать имена переменных строчными буквами с делением слов через нижние подчёркивания. Вот так: eto_imya_peremennoy, такой способ ещё называют снейк-кейс — змеиная нотация. Нотацией называют вот эти вот способы написания.
Если пишете имя переменной из одной буквы, то обычно пишут строчную, например: g. Не используйте строчную эль и заглавную ай, а ещё букву о. Потому что строчная латинская l выглядит как заглавная I в некоторых шрифтах. Ну а O похожа на ноль.
В целом, можете выбирать то, как удобно вам, если ваш код не будут читать посторонние. Если будут, то по хорошему надо бы его причёсывать под стандарты. Ну и в целом лучше давать «длинные» имена переменным, по которым понятно, что в них «лежит». Это упрощает последующее чтение кода.
Если берёте список воздуховодов из модели и далее обрабатываете его внутри цикла, то лучше писать код в таком виде: for duct in duct_list. То есть переменную со списком воздуховодов мы так и называем, чтобы было понятнее, что там хранится. Переменная, которую используем внутри цикла, возможно, больше нигде не пригодится, но всё равно лучше дать ей понятное имя, а не просто d или i.
Переменную для цикла называют i обычно только в том случае, если цикл проходится по списку чисел, например от 0 до 9 или вроде того. В переменную i засовывают счётчик, вот как-то так принято стало.
Работа со строками (текстом)
Текстовые данные в программировании обычно называют строками, от английского string. В Питоне строка — это текст в двойных или одинарных кавычках, ставьте, какие больше нравятся.
Поскольку мы часто будем работать с параметрами элементов из Ревита, то во многих случаях параметры будут текстовыми, то есть мы будем получать текст и дальше его как-то обрабатывать. В моей работе обычно это генерация каких-нибудь марок или артикулов, а также наименования для элементов.
Например, почти в каждой моей платной библиотеке трубопроводов есть скрипт Динамо, который формирует наименование для трубы, заполняет артикул, количество и массу. Наименование и артикул — текстовые данные, то есть мне их нужно как-то обрабатывать.
Самая частая операция, которую провожу со строками, — это их сложение. В программировании оно называется конкатенацией. Записывается так же, как сумма двух чисел, через знак плюс.
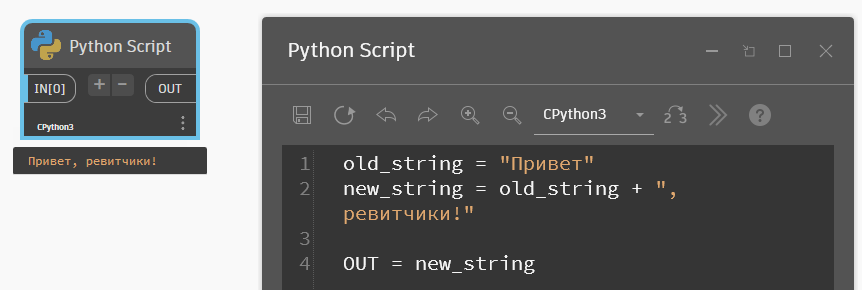
old_string = "Привет"
new_string = old_string + ", ревитчики!"
OUT = new_string
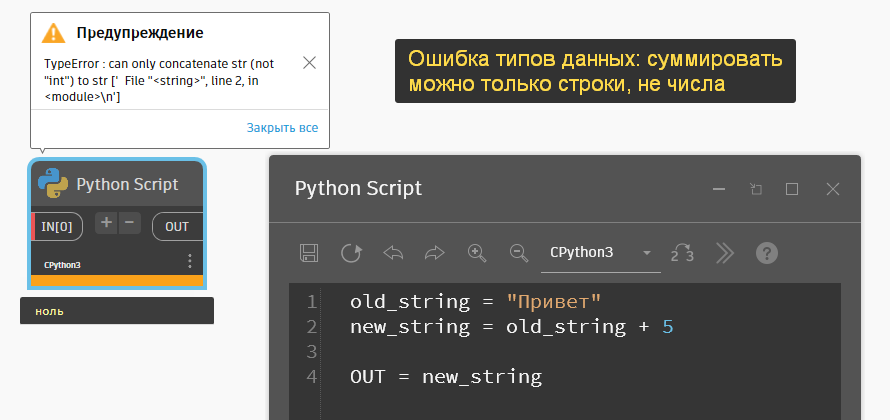
# в результате на выходе из Питон-нода получим текст "Привет, ревитчики!"Если будете складывать неподходящие данные, то получите ошибку. Нельзя сложить текст и число, например. Для этого число нужно сперва преобразовать в текст. Об этом будет чуть ниже, так как это важная составляющая работы.
У строки можно узнать длину — по сути это количество символом в строке. Делается это специальной функцией len(строка). В скобках нужно указать переменную с текстом, ну или прямо текст в кавычках. Функция вернёт целое число. В целом, не могу сказать, что часто пользуюсь ею, но она может пригодиться для анализа значений.
Здесь и далее, когда я пишу команду Питона и что-то рядом с ней на русском, то воспринимайте русский текст как пояснение, а не формат записи. len(строка) — здесь len() команда, а текст «строка» в скобках — пример того, что подаём в скобках.
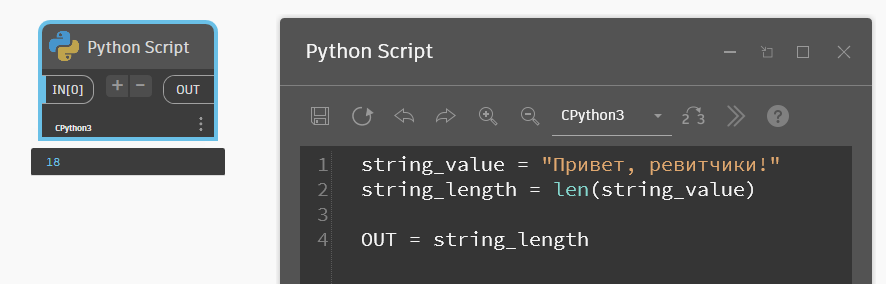
string_value = "Привет, ревитчики!"
string_length = len(string_value)
OUT = string_length
//в результате на выходе из Питон-нода увидим значение 18Для работы со строками существуют специальные методы. Например, есть метод, который заменяет определённые символы в строке. По сути, ноды в Динамо делают то же самое, просто там вам не нужно писать код вручную. Иногда нодами решить задачу быстрее тупо из-за того, что накидать их и соединить лапшой получается быстрее, чем писать код.
Но если мы решаем задачу внутри Питона и не хотим выходить из алгоритма, то надо писать код.
Давайте рассмотрим простейший пример: у нас есть имя системы трубопроводов, в нём Ревит по умолчанию ставит пробел. Нам нужно убрать пробел. Сделать это можно разными способами, самый простой — заменить символ пробела на пустую строку. Пустая строка обозначается как текст в кавычках, но без текста — "". В формулах Ревита такое тоже есть.
Обычно методы записываются так: строка.метод(). В скобках может быть что-то, а может и не быть, это зависит от метода. Содержимое скобок называют аргументами. В нашем случае будет метод replace(что заменяем, на что заменяем), то есть тут два аргумента. Выглядеть в коде это будет так:
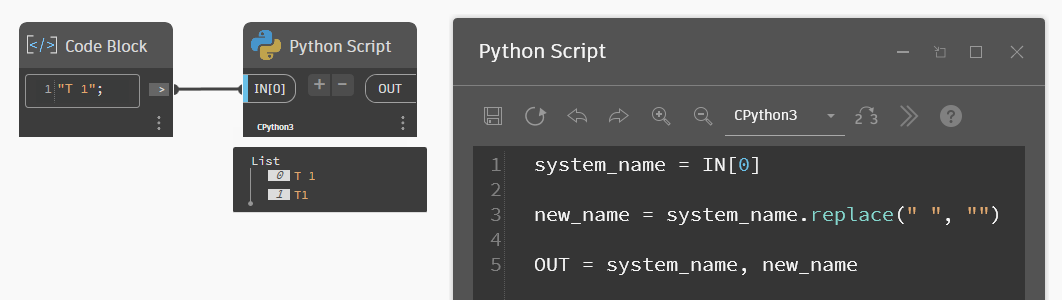
system_name = IN[0]
new_name = system_name.replace(" ", "")
OUT = system_name, new_nameВ переменную OUT я подал две другие переменные, в итоге они выводятся списком. Обратите внимание, что после применения метода исходная строка не изменилась. Я создал новую переменную для заменённого значения и вывел её в OUT. Это общее для всех строк — методы не меняют изначальную строку.
Можно извратиться и сделать иначе: разделить строку по пробелу, а потом сшить новые значения вместе. Или найти порядковый номер пробела, срезать строку до и после, а потом сшить значения. Эти методы требуют больше манипуляций, поэтому пользоваться ими довольно глупо, но в учебных целях норм.
Метод для разделения строк — split(разделитель). Собственно, как и нод в Динамо, в нод мы по сути подаём строку и аргумент в метод. Результат будет тот же, что и в Динамо: разделитель выкидывается, а исходная строка превращается в список из значений до разделителя и после.
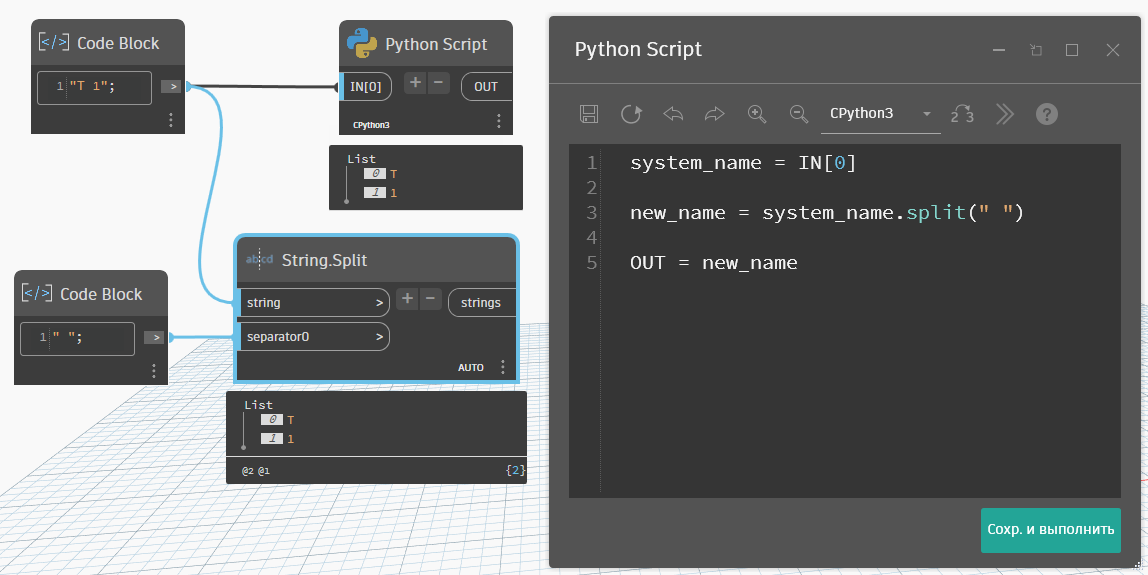
Список — это, конечно, хорошо, но нам-то нужно одну строчку с новым именем системы. Сделать это можно с помощью другого метода — разделитель.join(список строк). Тоже похоже на динамовский нод. Здесь нужно указать разделитель строк, а в скобках дать список из строк для объединения. Выглядит это так:
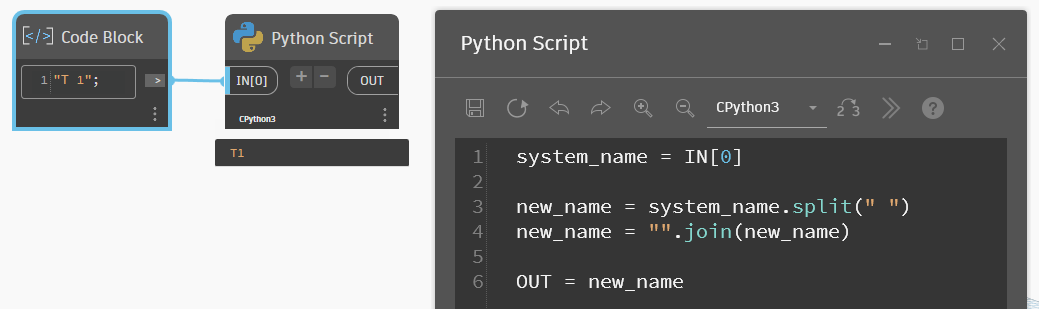
Мы можем соединять методы и применять их последовательно в одной переменной. Так делать не всегда хорошо, тут нужно руководствоваться удобностью чтения. Если получается слишком длинная запись, то это плохо читается, лучше поделить на несколько переменных. В нашем примере два метода, их можно объединить вот так:
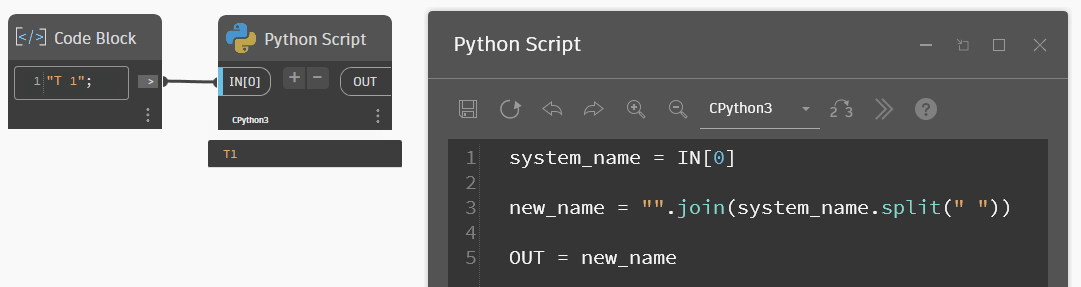
Сначала выполняется сплит, потом джоин. На выходе то же самое. Но это не очень хороший вариант, его сложнее читать — лучше оставлять по две переменные. И имена им дать разные, например сначала splitted_system_name, потом уже new_name.
Так как строка сама по себе является итерируемым объектом, то есть по ней можно пройтись циклом, то для строк можно делать срезы — обращаться к символам через индексы. На картинках ниже пример цикла, которым прохожусь по строке и вывожу каждый символ отдельно в список, на втором примере — беру индекс 0 и получаю первый символ из строки.
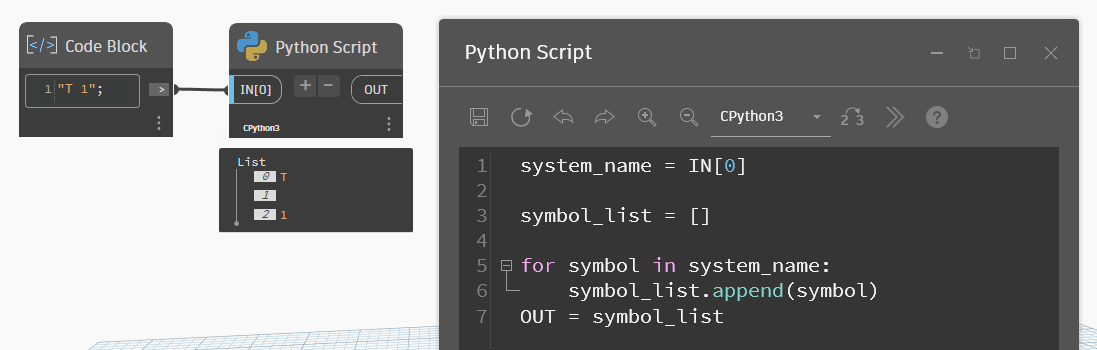
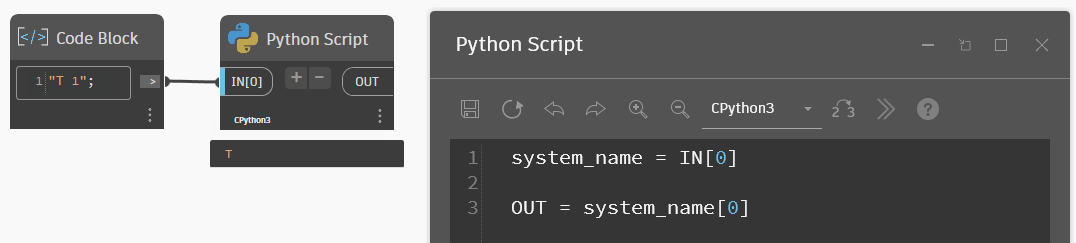
Для наглядности в примерах далее возьму более длинный текст: "Привет, ревитчики!".
Индекс — это порядковый номер символа в строке. Все отсчёты в программировании начинаются с нуля, а не с единицы, потому что в двоичном коде и логике байтов компьютеру так удобнее. Ну и это чуть побыстрее, а в эпоху, когда компьютер был огромным, а вычислительная мощность небольшая, даже это было важно. Так человечество впервые прогнулось под машины.
Соответственно, если мы пишем код в виде строка[4], то тем самым мы извлекаем из строки её пятый символ, 4+1, так как начинали мы с нуля. Более того, мы можем делать «срезы» — указывать диапазоны, откуда берём символы. Делается это через двоеточие: строка[0:4] — вот так берём первые четыре символа с самого начала. Последнее число является границей диапазона, этот индекс не берётся. То есть читается так: берём символы с нулевого до четвёртого невключительно.
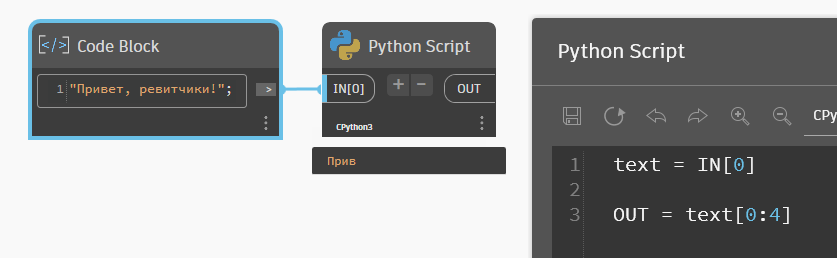
Если не указывать начало и конец среза, то по умолчанию будет браться начало и конец строки. Вот пример для среза с самого начала и от указанного символа до конца строки.
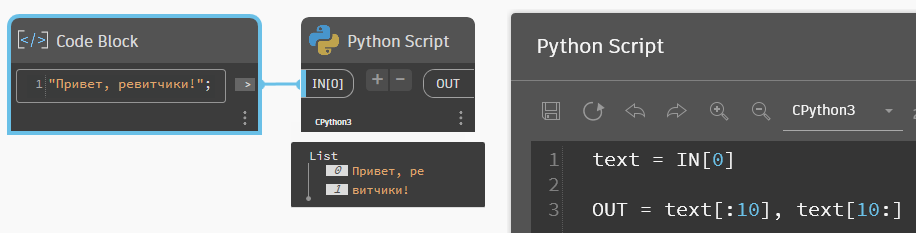
Теперь вернёмся к нашему имени системы и используем срезы. Сперва нужно найти, а какой по номеру символ в строке пробел. Делается это методом find(что ищем). Этот метод возвращает индекс символа, если он есть в строке, и -1, если символа нет. Например, в условных выражениях можете проверять, есть ли указанный текст в строке: if строка.find(что ищем) == -1 — такое выражение вернёт True, если текста в строке нет.
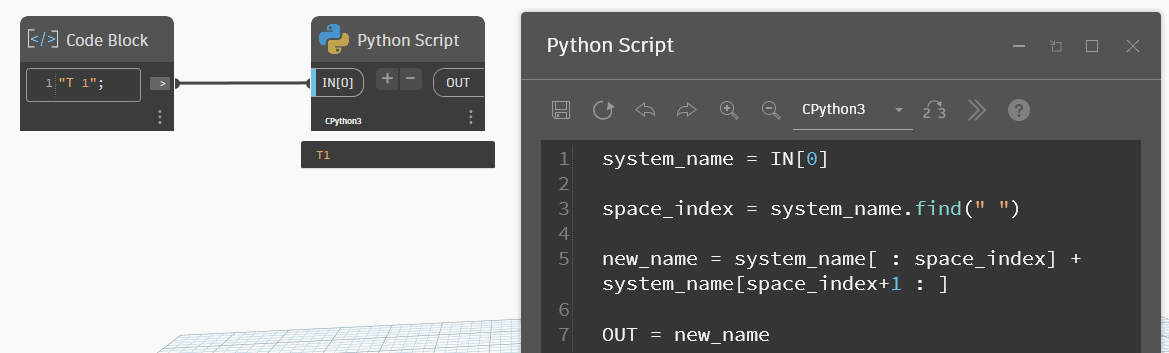
system_name = IN[0]
space_index = system_name.find(" ")
new_name = system_name[ : space_index] + system_name[space_index+1 : ]
OUT = new_nameИтак, что тут происходит. Сначала методом find ищем пробел. Он там есть, поэтому получаем его индекс. У нас тут буква Т — 0, пробел — 1, единица — 2. И метод вернул нам индекс пробела, то есть 1.
Далее берём срез от начала строки до пробела. Пробел включать не нужно, но в срез и не идёт последний индекс, поэтому пишем system_name[ : space_index] — эта запись будет брать символы от нулевого до индекса из переменной space_index невключительно. Так мы получаем букву Т.
Потом берём второй срез, но надо взять символы после пробела, то есть исключить пробел из выбора. Поэтому срез выглядит так: system_name[space_index+1 : ] — я прибавляю единицу к индексу пробела, чтобы срез брался со следующего символа после пробела. И там уже до конца строки все символы. По факту тут мы взяли символ «1».
И так как оба среза мы соединяем суммой, конкатенацией строк, то на выходе получаем значение без пробела. Вот вроде бы ерунду сделали, а сколько всего посмотрели, благодать сплошная.
Здесь мы с вами посмотрели на примеры работы с некоторыми методами. Они так или иначе работают по схожей логике, поэтому посмотрите на список методов в интернете, например вот тут. Если работали со строками в Динамо, то тут много похожего.
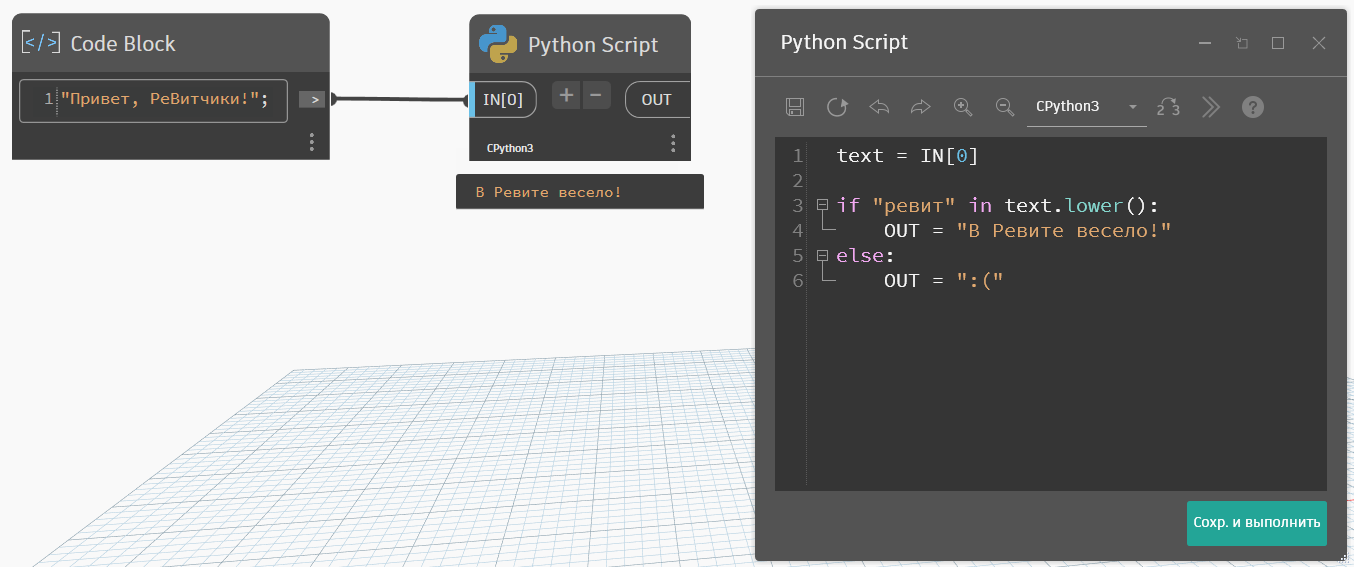
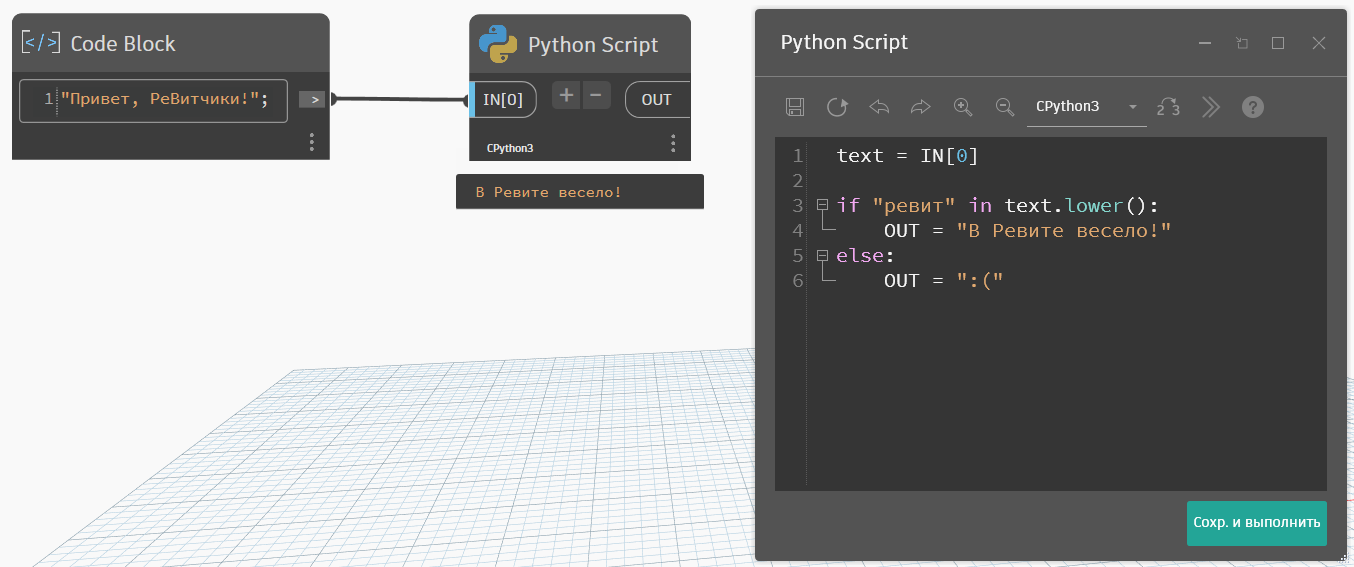
Если выполняете поиск по строке, то иногда есть смысл перевести все символы в нижний регистр методом строка.lower(). В этом случае все буквы станут строчными и не нужно будет проверять варианты с заглавными буквами. Но только в тех ситуациях, где регистр не важен.
В случаях, когда пишем условное выражение по поиску текста в тексте, то иногда гораздо удобнее воспользоваться не методами, а вот такой формой записи: if "искомое" in "текст для поиска". Такая форма записи выдаёт не индекс найденного, как метод find, а сразу true или false. Так что когда нужно установить сам факт наличия без индекса вхождения, то пользуйтесь этим синтаксисом.
Перевод чисел в текст
Ещё одна супер важная тема, с которой вы точно столкнётесь. Например, получаете из модели диаметры трубы или размеры окна. Для Динамо и Питона это определённый тип данных — дробные числа, double. Если записывать в наименование эти данные, то вам нужно перевести их в текст. В Питоне есть для этого разные способы, давайте на них посмотрим.
Я не буду рассматривать регулярные выражения, я в них не шарю.
Но прежде небольшое отступление про числа. В программировании бывают разные числа, самое простое деление — целые и дробные. Целые обычно называют integer, а дробные в Питоне — float. В Си шарпе один из видов дробных чисел называется double. Именно этот тип числа вы будете видеть в Ревит Лукапе для большинства числовых параметров вроде длины или расхода.
С точки зрения работы с текстом целые числа очень удобны, а вот дробные могут доставлять проблемы. Сейчас на это посмотрим.
Функция str()
Самое простое, что можно сделать, — перевести число в строку функцией str(число). Она преобразует любые числа в строки.
Тут есть подвох. Если преобразовываем целое число, то всё прекрасно меняется. Если подаём дробное, то тут возможны нюансы. На картинке ниже создаю два числа в левом Код Блоке. Оба они целые. Во втором Код Блоке превращаю целое в дробное. Динамовским нодом Object.Type показываю их типы данных. Тут же преобразовываю эти числа Динамовскими нодами и в Питоне.
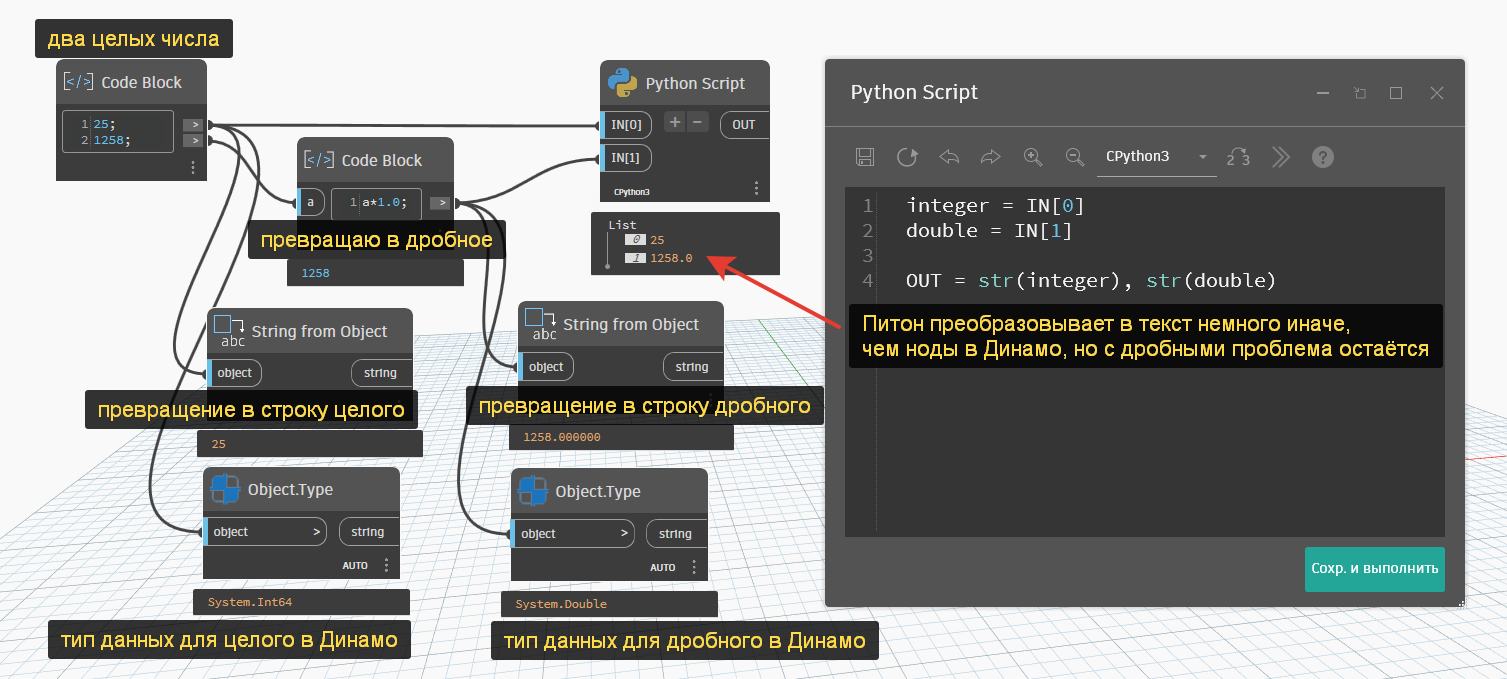
Как видите, преобразование дробного в текст, если у него нет видимой дробной части, приводит к появлению нулей после точки (или запятой, смотря какие настройки Винды у вас). Это называется trailing zeros.
Нужно отличать: есть дробное число само по себе, например 12.89, а есть дробное по типу данных, при этом визуально оно может быть как с дробной частью, так и без неё. И при преобразовании таких чисел без видимой дробной части мы получаем лишние нули.
Иногда это не баг, а фича. Например, когда пишем толщину стенки трубы в формате 16х2.0 и нужно указывать этот ноль. Но часто это мешает, поэтому от таких нулей надо избавляться.
Метод rstrip()
Метод строка.rstrip() предназначен для отрезания лишних пробелов в строке, когда они идут в её конце. Но если в скобках написать текст, то отрезать будет уже его, а не пробел. То есть в нашем случае запись будет такая: строка.rstrip(".0").
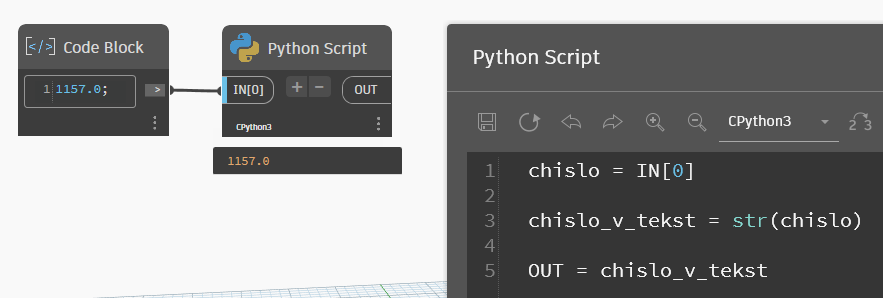

Кажется, всё супер, но тут тоже есть подвох. Если в код подать число с нулем в конце целой части, то такой метод откусит нам лишний ноль.
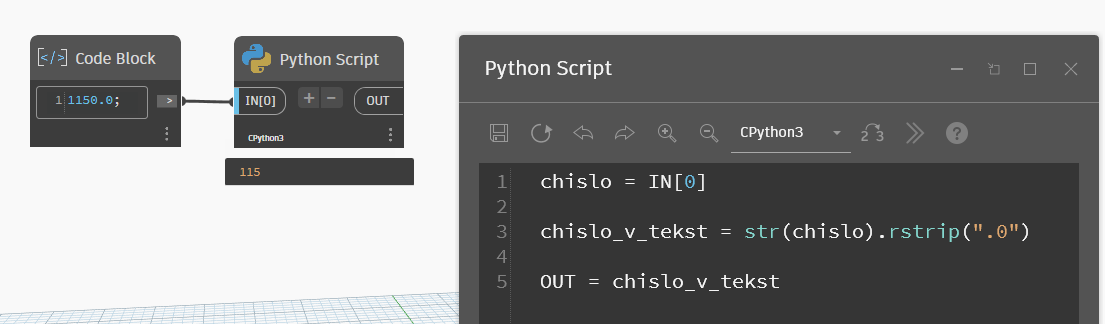
Вместо 1150 получилось 115 — ноль на конце тоже отбросился. Я не знаю, почему, но вот так оно работает. Однако если немного переписать и удалять двумя методами последовательно, то всё отлично работает:
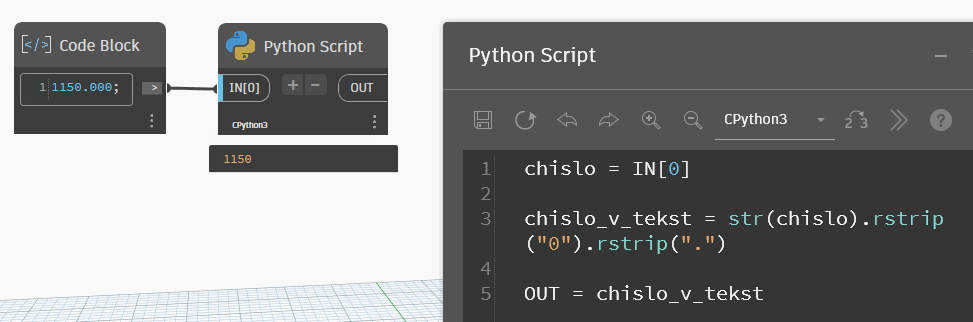
chislo = IN[0]
chislo_v_tekst = str(chislo).rstrip("0").rstrip(".")
OUT = chislo_v_tekstСобственно, этим методом я и пользуюсь для преобразования чисел в текст. Причём, иногда преобразовываю числа в текст Динамовскими нодами, а уже потом Питоном причёсываю текст, чтобы убрать лишние нули. При преобразовании в текст с помощью нодов Динамо мы получим не один ноль после запятой, а шесть нулей. И два последовательных метода rstrip() с ними тоже отлично справляются.
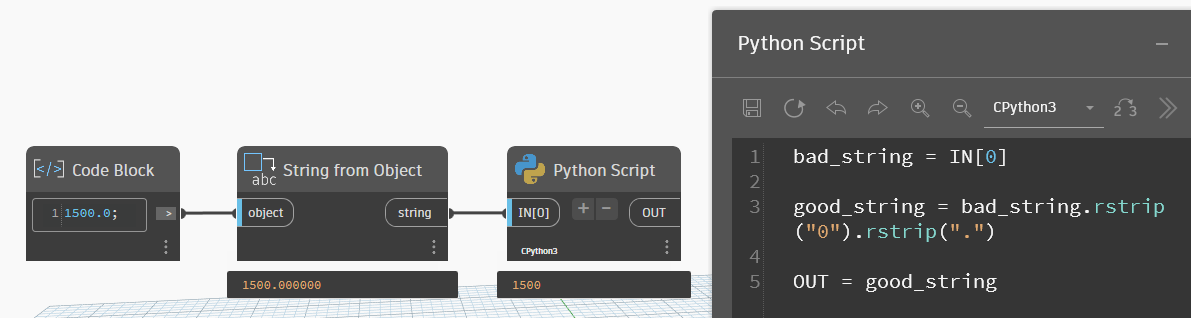
Форматирование строк
Мы можем создавать текстовые шаблоны выражений, в которые подставляем значения переменных. Например, если генерируем наименование чего-нибудь и там есть фиксированная форма, в которой меняются какие-то отдельные значения. Те же наименования труб, окон, воздуховодов или фитингов. Давайте посмотрим на примере фитинга трубы.
У нас есть отвод, в наименование нужно вывести его диаметр и угол. Обе характеристики числовые, поэтому предварительно переведём их в текст, так как встроенное форматирование Питона будет переводить эти данные в текст с точкой и нулём, а нам так не надо. Я сгенерирую диаметр и угол в Код Блоке и запишу их с точка-ноль, чтобы в Питоне пришли дробные, а не целые числа. Из Ревита вы такие данные получите именно как дробные числа, пусть и выглядящие целыми.
Далее форматирование выглядит так: "текст со ссылками".format(переменные)
Ссылки пишутся в виде {0}, {1} и так далее, где 0, 1 и далее — это номера переменных в скобках метода format. Если ссылка одна, то можно написать просто фигурные скобки без цифры {}. При формировании записи Питон будет брать значения переменных и засовывать в текст в указанные места. Вот так выглядит запись:
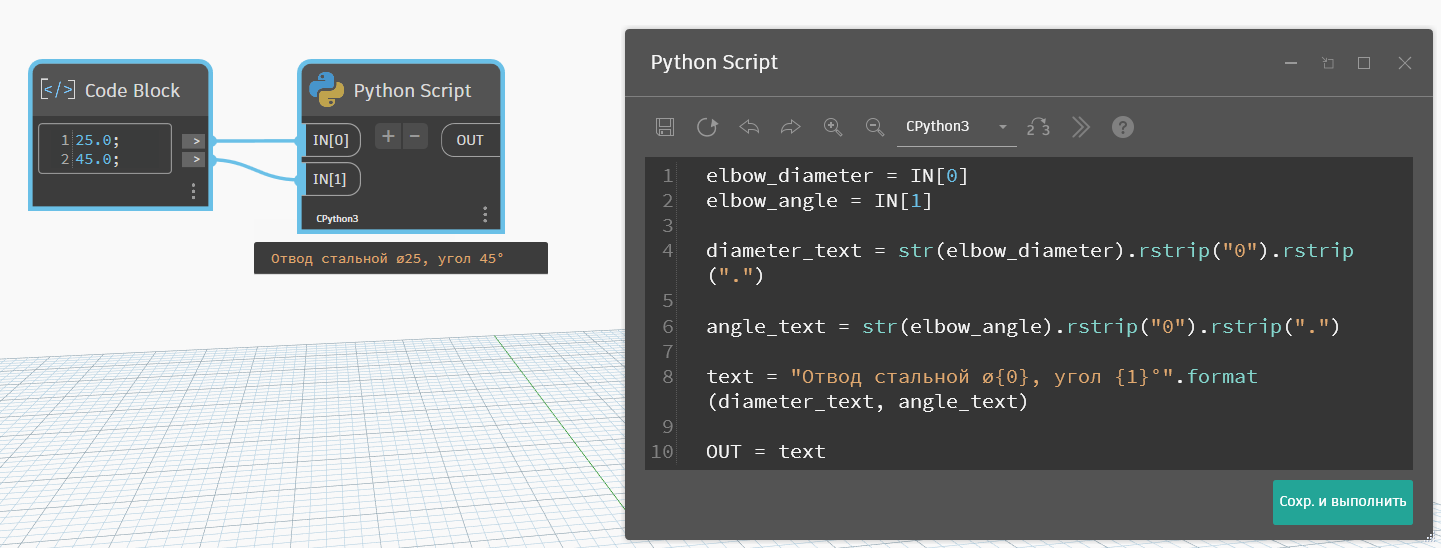
elbow_diameter = IN[0]
elbow_angle = IN[1]
diameter_text = str(elbow_diameter).rstrip("0").rstrip(".")
angle_text = str(elbow_angle).rstrip("0").rstrip(".")
text = "Отвод стальной ø{0}, угол {1}°".format(diameter_text, angle_text)
OUT = text"Отвод стальной ø{0}, угол {1}°".format(diameter_text, angle_text) — здесь у меня две ссылки, поэтому в фигурных скобках стоят номера 0 и 1, а дальше в аргументы метода format подаю переменные с нужными мне значениями и в том порядке, в каком идёт нумерация в ссылках.
Каждый раз, как значения переменных будут меняться, будет меняться и текст.
В принципе, это то же самое, что запись с помощью сложения строк, она будет чуть более громоздкой, но тоже будет работать:
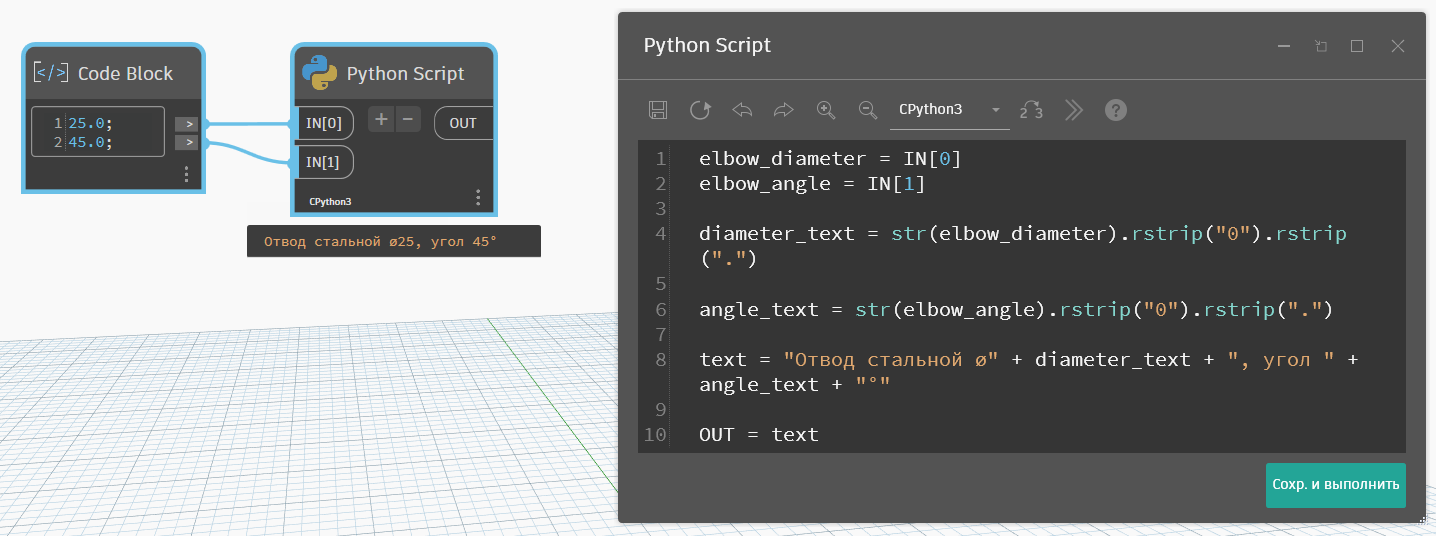
elbow_diameter = IN[0]
elbow_angle = IN[1]
diameter_text = str(elbow_diameter).rstrip("0").rstrip(".")
angle_text = str(elbow_angle).rstrip("0").rstrip(".")
text = "Отвод стальной ø" + diameter_text + ", угол " + angle_text + "°"
OUT = textФорматирование немного проще читается, но по факту я частенько делаю именно конкатенацию.
На деле мы можем менять формат записи наших чисел, то есть не переводить их предварительно в текст. Для этого нужно подписывать специальные плейсхолдеры. Вот пример форматирования без этих плейсхолдеров, когда я напрямую подаю числа в форматирование:
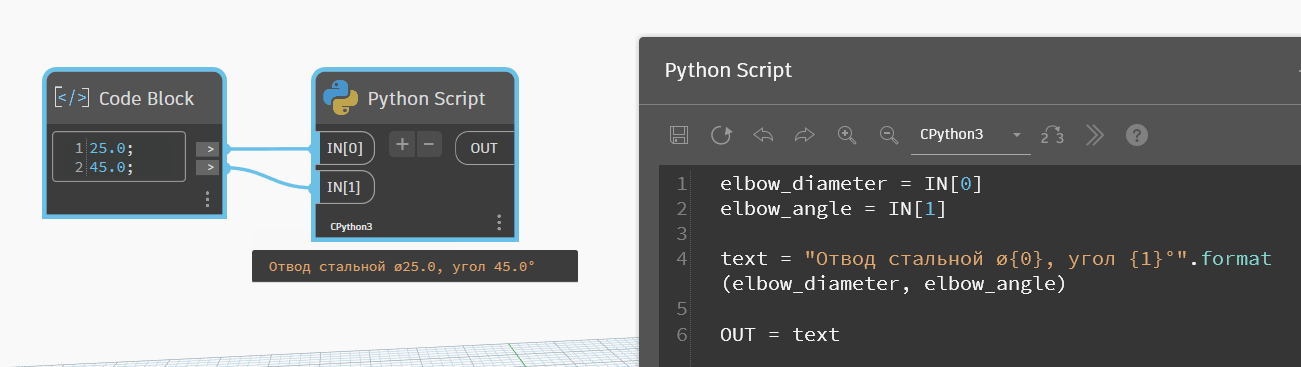
Как видите, тут снова получаем дополнительные нули после точки.
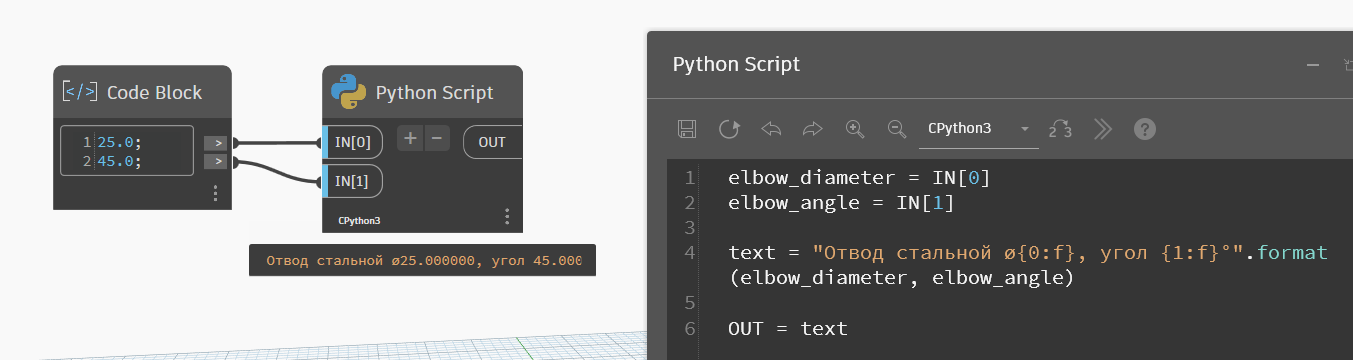
Для дробных чисел есть специальный плейсхолдер — f. Его пишут так: {0:f}. В этом случае у чисел при переводе в текст появляются те самые шесть нулей, как при переводе нодами Динамо:
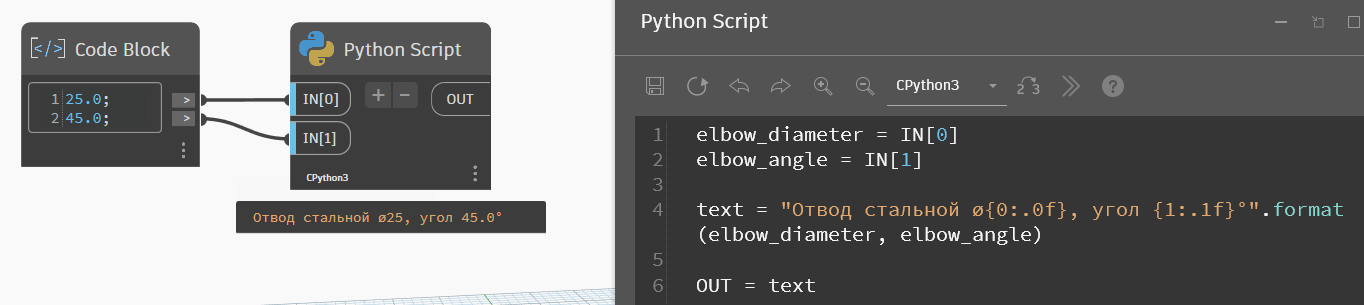
Но запись можно изменить на {0:.0f} — это будет означать, сколько знаков после запятой оставлять.
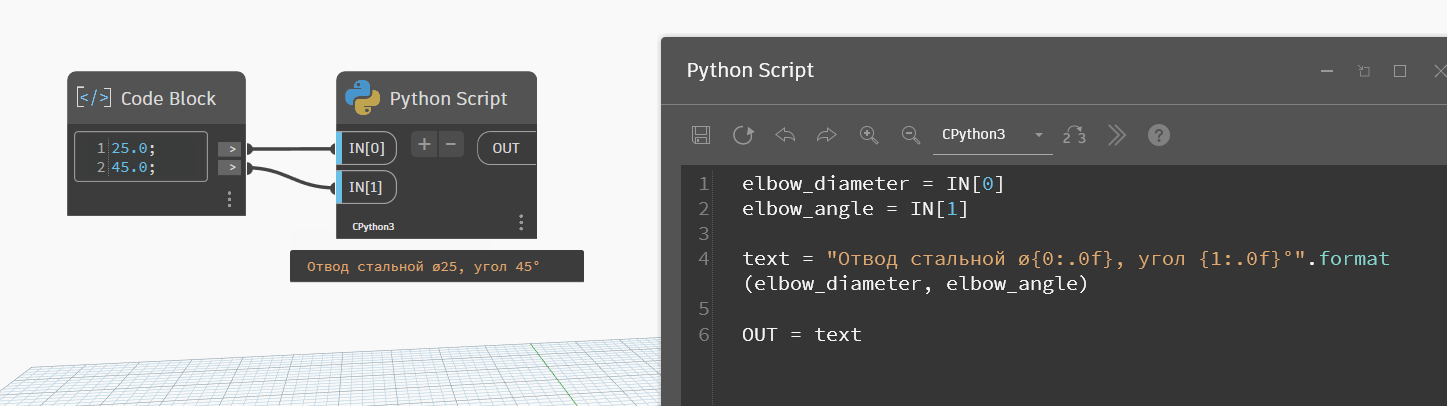
Казалось бы: ну вот оно, победа! Но не совсем. Так действительно удобнее переводить значения в текст, но формат записи предполагает, что знаки после запятой будут отбрасываться всегда, даже тогда, когда это не нужно. Например, у отвода будет угол 22.5° — именно так нам и нужно его записывать в спецификацию, но подобная настройка форматирования не даст нужный результат:
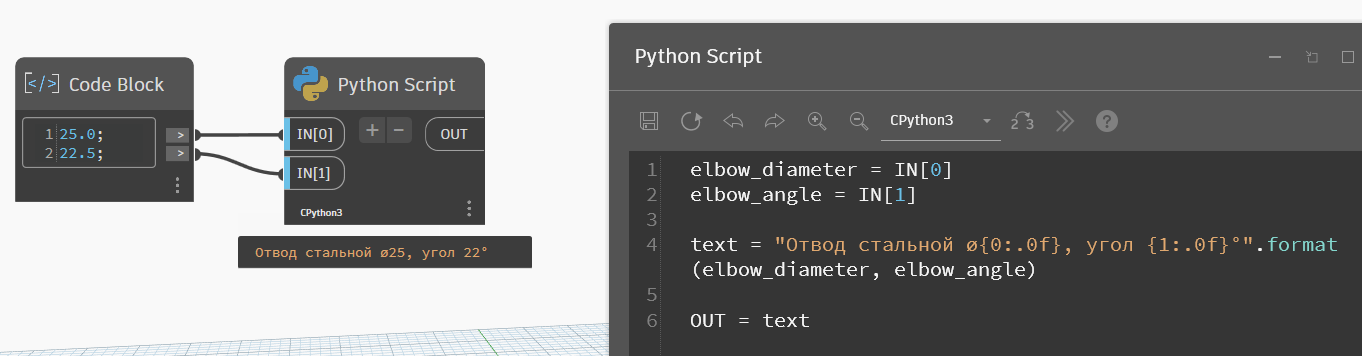
elbow_diameter = IN[0]
elbow_angle = IN[1]
text = "Отвод стальной ø{0:.0f}, угол {1:.0f}°".format(elbow_diameter, elbow_angle)
OUT = textКак видите, вместо 22.5° мы получаем 22° — потому что в форматировании стоит 0 знаков после запятой. Если поставить 1 знак, то получим наши 22.5°, но когда угол будет целым, мы получим лишний ноль в записи. И от него всё равно придётся каким-то дополнительным алгоритмом избавляться, что делает форматирование не очень удобным. Хотя тут всё зависит от того, какой формат записи вам нужен, иногда он вполне подходит.
Больше про форматирование можете почитать на сайте Метанита.
В будущем покажу, как создавать свои функции, в том числе и для перевода чисел в текст. С её помощью мы не будем каждый раз писать утомительный алгоритм для преобразования чисел, а будем пользоваться одной готовой командой.
Итоги по работе со строками
Регистр — важен! Компьютер не работает с буквами напрямую, каждый символ преобразовывается в набор нулей и единиц, поэтому для большой и малой буквы наборы будут разными.
Работать с ними будете много, поэтому полезно изучить методы. По сути нужно знать те же методы, которые вы применяете к строкам в Динамо. Найдите метод, изучите синтаксис и готово.
Методы не меняют исходную строку, то есть возвращает её же, поэтому нужно «засовывать» результат работы метода в новую переменную или перезаписывать старую.
Строки можно складывать через знак плюс. Ещё строку можно умножать, тогда она будет повторяться столько раз, сколько стоит число в произведении. Возможность есть, но мне она никогда не пригождалась.
Функция len() посчитает количество символов в строке.
Можно проверить, есть ли символы в строке, с помощью записи if символы in строка.
Важно найти удобный способ для перевода чисел в текст, чтобы делать красивые наименования.
Форматирование строк пригождается не всегда, но если подходит — пользуйтесь.
Если статья помогла разобраться со строками и переменными — пишите в комментарии, расскажите, чем она была вам полезна.

